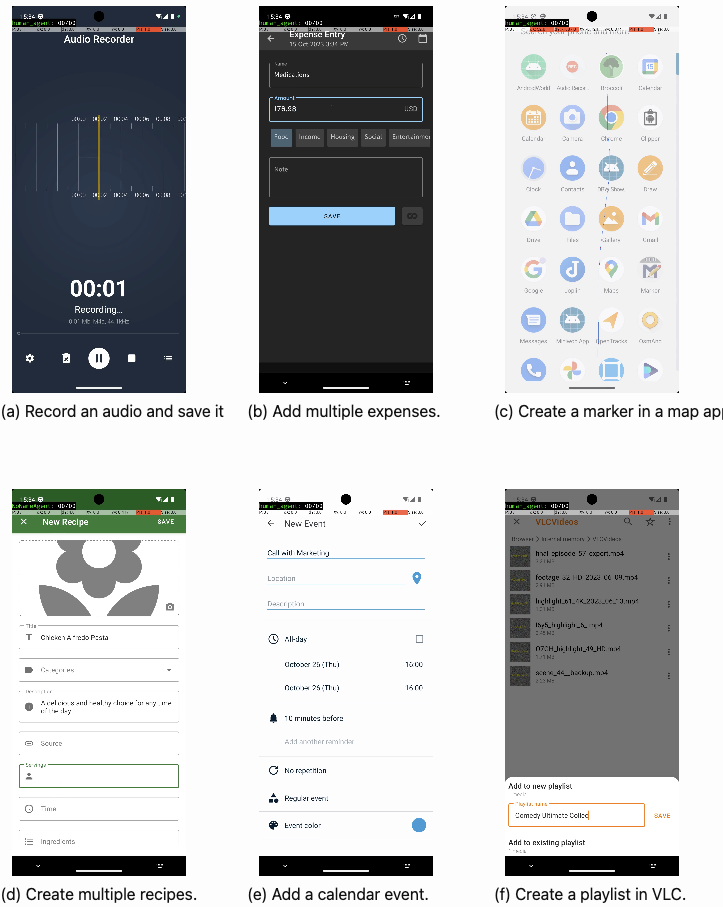
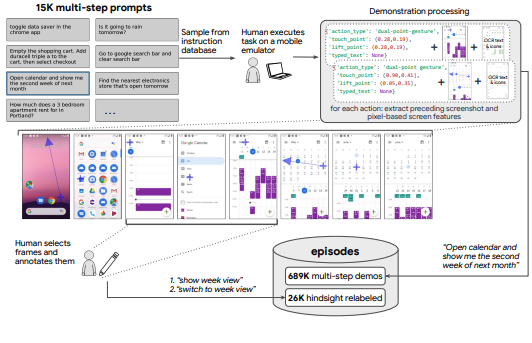
Reinforcement Learning on Google Cloud
Training deep RL agents can be expensive in terms of both computing resources and time. It is common for an algorithm to take tens of thousands or millions of simulation/training steps before one observes the accumulated rewards start to rise. And it can take a lot more from there for the algorithm to converge. For example, in a paper from DeepMind they indicated it took approximately 20 epochs (1 epoch = 0.5 hour according to the paper) before the agent showed clear signs of learning. The entire process took 100 epochs, and yet that was only a single trial!
Furthermore, RL problems are notoriously sensitive to hyperparameters, which means it’s necessary to evaluate many different hyperparameters.
Using these factors as motivation, in this post, we show how to train many jobs in parallel using Google Cloud’s hyperparameter tuning service with ML Engine. This service gives you two key benefits:
- You can train many models in parallel, this allows you to quickly iterate your concept and you only pay for the compute resources you use in each job.
- You benefit from the managed hyper-parameter tuning service, which typically results in quicker convergence than just using a naïve grid search.
View the full article