sql_magic: Jupyter Magic for Apache Spark and SQL databases
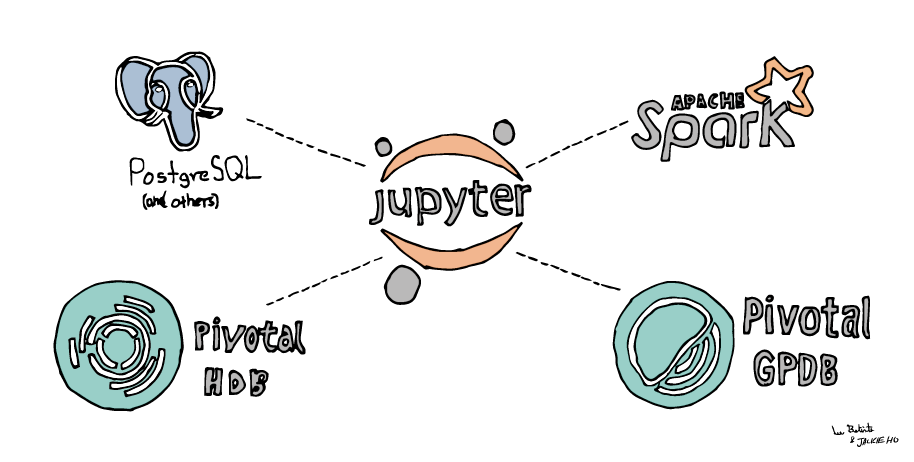
Data scientists love Jupyter Notebook, Python, and Pandas. And they also write SQL. I created sql_magic to facilitate writing SQL code from Jupyter Notebook to use with both Apache Spark (or Hive) and relational databases such as PostgreSQL, MySQL, Pivotal Greenplum and HDB, and others. The library supports SQLAlchemy connection objects, psycopg connection objects, SparkSession and SQLContext objects, and other connections types. The %%read_sql magic function returns results as a Pandas DataFrame for analysis and visualization.
%%read_sql df_result
SELECT {col_names}
FROM {table_name}
WHERE age < 10
The sql_magic library expands upon current libraries such as ipython-sql with the following features:
- Support for both Apache Spark and relational database connections simultaneously
- Asynchronous execution (useful for long queries)
- Browser notifications for query completion
# installation
pip install sql_magic
Check out the GitHub repository for more information.
Links: